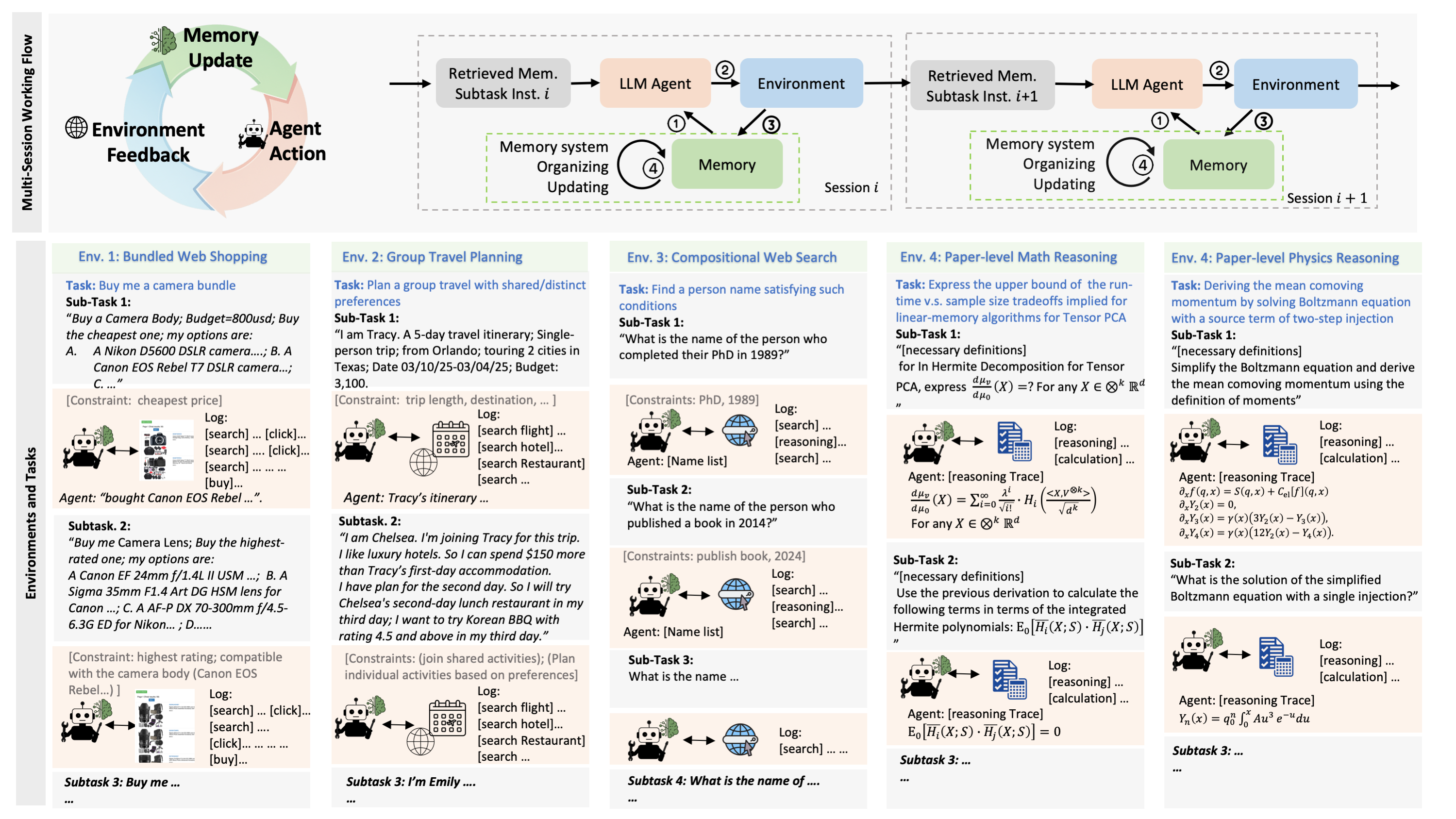
Existing evaluations of agents with memory typically assess memorization and action in isolation. One class of benchmarks evaluates memorization by testing recall of past conversations or text but fails to capture how memory is used to guide future decisions. Another class focuses on agents acting in single-session tasks without the need for long-term memory. However, in realistic settings, memorization and action are tightly coupled: agents acquire memory while interacting with the environment, and subsequently rely on that memory to solve future tasks.
To capture this setting, We introduce MemoryArena, a unified evaluation gym for benchmarking agent memory in multi-session Memory-Agent-Environment loops. The benchmark consists of human-crafted agentic tasks with explicitly interdependent subtasks, where agents must learn from earlier actions and feedback by distilling experiences into memory, and subsequently use that memory to guide later actions to solve the overall task. MemoryArena supports evaluation across web navigation, preference-constrained planning, progressive information search, and sequential formal reasoning, and reveals that agents with near-saturated performance on existing long-context memory benchmarks like LoCoMo perform poorly in our agentic setting, exposing a gap in current evaluations for agents with memory.
This dataset contains structured multi-session agentic tasks with questions (list), answers (list), and necessary background context or misc. Each row in the test file represents an agentic task (dict) with multiple subtasks, their corresponding answers, and background information.
Each line in the HuggingFace test file is a dictionary with the following fields:
Load with Hugging Face Datasets:
from datasets import load_dataset
ds = load_dataset("ZexueHe/memoryarena", "bundled_shopping")
ds = load_dataset("ZexueHe/memoryarena", "progressive_search")
ds = load_dataset("ZexueHe/memoryarena", "group_travel_planner")
ds = load_dataset("ZexueHe/memoryarena", "formal_reasoning_math")
ds = load_dataset("ZexueHe/memoryarena", "formal_reasoning_phys")
Bundled Webshop:
{
"id": 0,
"questions": [
"search subtask 1",
"search subtask 1",
...
],
"answers": [
"search subtask result 1",
"search subtask result 2",
...
]
}
Progressive Search:
{
"id": 0,
"questions": [
"buy subtask item1",
"buy subtask item 2",
...
],
"answers": [
{"target_asin": "B00TUDFEW2", "attributes": ["Almond Flour", ...]},
{"target_asin": "B08957C9ZH", "attributes": [...]},
...
]
}
Group Travel Planner:
{
"id": 0,
"base_person": {
"name": "Jennifer",
"query": "I am Jennifer. Please help me plan a trip from St. Petersburg to Rockford spanning 3 days...",
"daily_plans": [
{"days": 1, "current_city": "from St. Petersburg to Rockford", "transportation": "..."},
{"days": 2, "current_city": "Rockford", "transportation": "..."},
...
]
},
"questions": [
"I am Eric.\n I'm joining Jennifer for this trip...",
"I am Emma.\n I'm traveling with Jennifer and Eric...",
...
],
"answers": [
[
{"days": 1, "current_city": "from St. Petersburg to Rockford", "transportation": "..."},
{"days": 2, "current_city": "Rockford", "transportation": "..."},
...
],
[
{"days": 1, "current_city": "from St. Petersburg to Rockford", "transportation": "..."},
{"days": 2, "current_city": "Rockford", "transportation": "..."},
...
],
...
]
}
Formal Reasoning (Math and Phys):
{
"id": 0,
"paper_name": "paper_id",
"backgrounds": [
"necessary definitions, formulations, and relevant context of subtask 1",
"necessary definitions, formulations, and relevant context of subtask 2",
...
],
"questions": [
"Math subtask question 1",
"Math subtask question 2",
...
],
"answers": [
"Math result for subtask 1",
"Math result for subtask 2",
...
]
}
This dataset is licensed under the Creative Commons Attribution 4.0 International (CC-BY-4.0) license.
If you use this dataset, PLEASE CITE THE NEW BIBTEX:
@article{he2026memoryarena,
title={MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks},
author={He, Zexue and Wang, Yu and Zhi, Churan and Hu, Yuanzhe and Chen, Tzu-Ping and Yin, Lang and Chen, Ze and Wu, Tong Arthur and Ouyang, Siru and Wang, Zihan and others},
journal={arXiv preprint arXiv:2602.16313},
year={2026}
}